The Exact, Algebraic Solution for Error Independent Binary Classifiers¶
This notebook will illustrate the exact, algebraic solution to error independent binary classifiers that is contained in the ntqr.r2.ErrorIndependentEvaluation class. It will be contrasted with another algebraic evaluator the reader may be familiar with - majority voting.
The polynomial generating set for error-independent binary classification sketches¶
The observations of agreement and disagreement vote patterns for noisy classification functions are not without structure. This can be seen in the polynomial generating set for three binary classifiers that are arbitrarily correlated. The idea of a “generating set” is that the data sketch of observations is explained by unknown statistics of correctness during a test that we want to estimate. In other words, the aligned decisions of binary classifiers and their resulting counts are not just random numbers. They follow a pattern that is given by the generating set of polynomials. Let’s take a peek at that complicated generating set for arbitrarly correlated classifiers.
import sympy
from IPython.display import Math, HTML
import ntqr
from ntqr.r2.plots import plot_evaluations
from ntqr.r2.paxioms import (
trio_binary_classifiers_generating_set,
pa, pb,
pia, pib, pja, pjb, pka, pkb,
gija, gijb, gika, gikb, gjka, gjkb,
gijka, gijkb)
#from ntqr.r2.datasketches import trio_vote_patterns
Matrix([expr for expr in trio_binary_classifiers_generating_set])
The set above is the one used to derive the axioms of evaluation for binary classification up to N=3. We want to test the error-independent solution so we want the generating set for error-independent binary classifiers. That is given by setting all the error correlations identically to zero.
zero_error_correlations = {gija: 0, gijb: 0,
gika: 0, gikb: 0,
gjka: 0, gjkb: 0,
gijka: 0, gijkb: 0}
error_independent_generating_set = [poly.subs(zero_error_correlations) for poly in trio_binary_classifiers_generating_set]
sympy.Matrix(error_independent_generating_set)
The structure of this generating set is the reason we can obtain information about the evaluation using only the observed frequencies that appear at the right. This can be stated precisely by saying that the data sketches of binary classifiers are not generated by eight random integers in an unstructured way as follows.
from ntqr.r2.paxioms import trio_frequencies
incorrect_generating_set = [(sympy.Symbol("x_{}".format(i)) - trio_frequencies[i-1]) for i in range(1,9)]
sympy.Matrix(incorrect_generating_set)
Another notebook will discuss the utility of this observation - not every set of vote pattern counts is admissible and therefore we can detect spoofed data sketches.
A round trip evaluation to demonstrate the exact solution¶
We can now demonstrate the exact solution for the case of error independent classifiers by using the generating set. We randomly pick values for all the statistics in the generating set, substitute them in the generating set to get the data sketch that would be observed in that case. We then use the data sketch to recover the stastics we used to generate the set.
# Let's simplify the substitution by using the relation between pa and pb
simplified_generating_set = [poly.subs({pb:(1-pa)}) for poly in error_independent_generating_set]
sympy.Matrix(simplified_generating_set)
from random import randint
from fractions import Fraction
# We do a random pick for the statistics
simulated_performance_statistics = {var:Fraction(randint(1,39),40) for var in [pa, pia, pib, pja, pjb, pka, pkb]}
# Using the polynomials above, we map the simulated performance statistics to what frequencies of decision
# patterns we would observe.
generated_data_sketch = [poly.subs(simulated_performance_statistics) for poly in simplified_generating_set]
sympy.Matrix(generated_data_sketch)
# Let's turn the voting frequencies back into integer counts
# First, we get the rational fractions.
# SymPy returns solutions wrapped in its own class FiniteSet, so we have to turn them back into lists
# to access the members
data_sketch_frequencies = list(sympy.linsolve(generated_data_sketch, trio_frequencies))[0]
print(data_sketch_frequencies)
(270313/2560000, 395007/2560000, 247567/2560000, 242313/2560000, 356527/2560000, 531753/2560000, 221593/2560000, 294927/2560000)
import math
maxDenominator = math.lcm(*[val.denominator for val in data_sketch_frequencies])
data_sketch_integers = [int(val*maxDenominator) for val in data_sketch_frequencies]
print(data_sketch_integers)
import itertools
trio_decision_patterns = sorted(itertools.product(['a','b'],repeat=3))
trio_vote_patterns = [pattern for pattern in trio_decision_patterns]
# And now we turn them into a data_sketch with their vote patterns
trio_decision_patterns = sorted(itertools.product(['a','b'],repeat=3))
trio_vote_patterns = [pattern for pattern in trio_decision_patterns]
vote_pattern_counts = {trio_vote_patterns[i]: data_sketch_integers[i] for i in range(8)}
vote_pattern_counts
{('a', 'a', 'a'): 270313,
('a', 'a', 'b'): 395007,
('a', 'b', 'a'): 247567,
('a', 'b', 'b'): 242313,
('b', 'a', 'a'): 356527,
('b', 'a', 'b'): 531753,
('b', 'b', 'a'): 221593,
('b', 'b', 'b'): 294927}
from ntqr.r2.evaluators import ErrorIndependentEvaluation
from ntqr.r2.datasketches import TrioVoteCounts
tvc = TrioVoteCounts(vote_pattern_counts)
evaluator = ErrorIndependentEvaluation(tvc)
eval_exact = evaluator.evaluation_exact
eval_exact
Note how the error independent solution is the best you could possibly do in an unlabeled setting - it returns just two points. In the language of algebraic geometry we would say that the variety (the set of possible solutions) of the error indepedent ideal (the generating set of polynomials) is zero dimensional and consists of two points. One of these two solutions should be an exact match with the random values you got when running this notebook.
simulated_performance_statistics
{P_a: Fraction(3, 40),
P_{i, a}: Fraction(31, 40),
P_{i, b}: Fraction(23, 40),
P_{j, a}: Fraction(3, 40),
P_{j, b}: Fraction(7, 20),
P_{k, a}: Fraction(31, 40),
P_{k, b}: Fraction(3, 5)}
Majority voting and algebraic evaluators¶
Majority voting (MV) is usually discussed in the ML/AI literature as a decision algorithm. But it can also be used to carry out algebraic evaluation by using those decisions to impute an answer key for the test. Note that this means that the MV algorithm is saying exactly what each item’s true label should be. This is to be contrasted with the solution presented here which is fully inferential since it never decides what the label of any item on the test should be.
The main problem with MV as an evaluator is that it cannot deal with the minority report situation. The crowd is not always right and there are cases where one classifier or two may be badly tuned. We are going to demonstrate that problem by doing a simulation of error independent classifiers that has a ‘flipped’ classifier.
# Let's pick all the classifiers above 50% performance to start with.
size_test=100
simulated_error_independent_performance = {var:Fraction(randint(0,size_test),size_test) for var in [pia, pib, pja, pjb, pka, pkb]}
# Then let's flip, say, classifiers j,k on the 'a' label below 50% accuracy
simulated_error_independent_performance[pja] = Fraction(randint(0,int(size_test/2)-1),size_test)
simulated_error_independent_performance[pka] = Fraction(randint(0,int(size_test/2)-1),size_test)
# And let's set the 'a' label prevalence to some number below 50%
simulated_error_independent_performance[pa] = Fraction(randint(1,int(size_test/2)-1),size_test)
smeip = simulated_error_independent_performance
print("P_i_a + P_i_b: {}".format(smeip[pia] + smeip[pib]-1))
print("P_j_a + P_j_b: {}".format(smeip[pja] + smeip[pjb]-1))
print("P_k_a + P_k_b: {}".format(smeip[pka] + smeip[pkb]-1))
P_i_a + P_i_b: -1/10
P_j_a + P_j_b: -27/50
P_k_a + P_k_b: -11/20
generated_data_sketch = [poly.subs(simulated_error_independent_performance) for poly in simplified_generating_set]
sympy.Matrix(generated_data_sketch)
data_sketch_frequencies = list(sympy.linsolve(generated_data_sketch, trio_frequencies))[0]
print(data_sketch_frequencies)
(464853/5000000, 247797/5000000, 437647/5000000, 824703/5000000, 9273/78125, 164439/2500000, 38533/312500, 743061/2500000)
maxDenominator = math.lcm(*[val.denominator for val in data_sketch_frequencies])
data_sketch_integers = [val*maxDenominator for val in data_sketch_frequencies]
print(data_sketch_integers)
[464853, 247797, 437647, 824703, 593472, 328878, 616528, 1486122]
vote_pattern_counts = {trio_vote_patterns[i]: data_sketch_integers[i] for i in range(8)}
vote_pattern_counts
{('a', 'a', 'a'): 464853,
('a', 'a', 'b'): 247797,
('a', 'b', 'a'): 437647,
('a', 'b', 'b'): 824703,
('b', 'a', 'a'): 593472,
('b', 'a', 'b'): 328878,
('b', 'b', 'a'): 616528,
('b', 'b', 'b'): 1486122}
tvc = TrioVoteCounts(vote_pattern_counts)
evaluator = ErrorIndependentEvaluation(tvc)
eval_exact = evaluator.evaluation_exact
eval_exact
[{'prevalence': {'a': 9/20, 'b': 11/20},
'accuracy': [{'a': 17/50, 'b': 14/25},
{'a': 3/100, 'b': 43/100},
{'a': 3/25, 'b': 33/100}]},
{'prevalence': {'a': 11/20, 'b': 9/20},
'accuracy': [{'a': 11/25, 'b': 33/50},
{'a': 57/100, 'b': 97/100},
{'a': 67/100, 'b': 22/25}]}]
Note that the error independent algebraic solution correctly picked up that classifier k (3) is actually below 50%. What does majority voting say?
from ntqr.r2.evaluators import MajorityVotingEvaluation
mv_estimate = MajorityVotingEvaluation(tvc)
How does the MV evaluation do?
%matplotlib inline
mv_exact = mv_estimate.evaluation_exact
size=40
plot_evaluations([
["algebraic evaluation",[d['a']*100 for d in eval_exact[0]["accuracy"]],
[d['b']*100 for d in eval_exact[0]["accuracy"]],
"^", "k",size],
["majority voting",[d['a']*100 for d in mv_exact[0]["accuracy"]],
[d['b']*100 for d in mv_exact[0]["accuracy"]],
"o", "g",size]],"A comparison of exact algebraic evaluation with MV",figsize=(7,6),legend_loc="best")
plt.show()
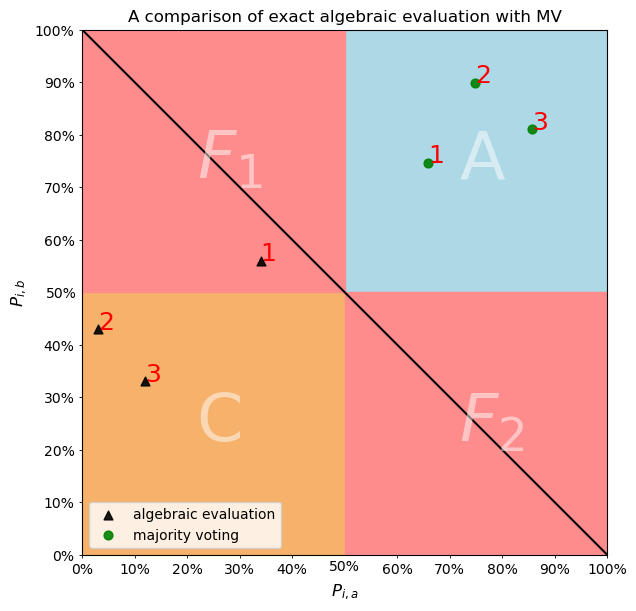
This figure encapsulates the huge advantage of algebraic evaluation over majority voting when it comes to the problem of AI safety. When things are going well, monitoring is useful but not critical. The most important reason for monitoring is the detection of misaligned or malfunctioning algorithms. We see in the figure above that MV thinks that all is well with classifier 2.